스마트 진행률 표시 줄 ETA 계산
많은 응용 프로그램에서 파일 다운로드, 압축 작업, 검색 등에 대한 진행률 표시 줄이 있습니다. 우리 모두는 종종 진행률 표시 줄을 사용하여 사용자에게 어떤 일이 일어나고 있음을 알립니다. 그리고 우리가 얼마나 많은 작업이 수행되었고 얼마나 남았는지와 같은 세부 사항을 알고 있다면, 우리는 종종 현재 진행 수준에 도달하는 데 걸린 시간을 추정하여 시간을 추정 할 수도 있습니다.

(출처 : jameslao.com )
{kind=link}
그러나 우리는 또한이 Time Left "ETA"디스플레이가 우스꽝스럽게 나쁜 프로그램을 보았습니다. 파일 복사가 20 초 안에 완료 될 것이라고 주장하고 1 초 후에 4 일이 걸릴 것이라고 말한 다음 다시 20 분으로 깜박입니다. 도움이되지 않을뿐만 아니라 혼란 스럽습니다! ETA가 너무 많이 다른 이유는 진행률 자체가 다를 수 있고 프로그래머의 수학이 지나치게 민감 할 수 있기 때문입니다.
Apple은 정확한 예측을 피하고 모호한 추정치를 제공함으로써이를 회피합니다! (출처 : autodesk.com )
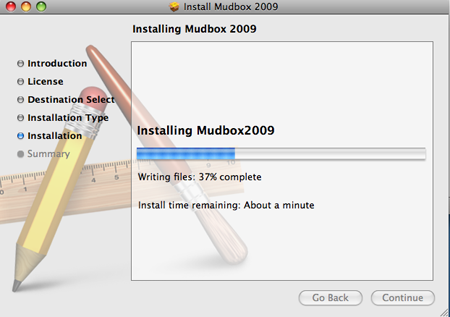{kind=link}
그것도 성가신 일입니다. 잠깐 휴식을 취할 시간이 있습니까, 아니면 2 초 후에 작업이 완료 될까요? 예측이 너무 모호하다면 어떤 예측도하는 것은 의미가 없습니다.
쉽지만 잘못된 방법
첫 번째 통과 ETA 계산으로, 아마도 우리는 p가 이미 완료된 분수 비율이고 t가 지금까지 걸린 시간 인 경우와 같은 함수를 만들 것입니다 .t * (1-p) / p를 추정값으로 출력합니다. 완료하는 데 걸리는 시간입니다. 이 단순한 비율은 "OK"로 작동하지만 특히 계산이 끝날 때 끔찍합니다. 느린 다운로드 속도로 인해 하룻밤 사이에 복사본이 느리게 진행되고 마지막으로 아침에 무언가가 시작되고 복사본이 100 배 더 빠르게 최대 속도로 진행되기 시작하면 90 % 완료의 ETA가 "1 시간", 10 초가 될 수 있습니다. 나중에 당신은 95 %가되고 ETA는 "30 분"이라고 말할 것입니다. 이것은 당황 스러울 정도로 좋지 않은 추측입니다.이 경우 "10 초"는 훨씬 더 나은 추정치입니다.
이런 일이 발생하면 평균 속도가 아닌 최근 속도 를 사용 하여 ETA를 추정 하도록 계산을 변경할 수 있습니다 . 지난 10 초 동안의 평균 다운로드 속도 또는 완료 속도를 취하고이 속도를 사용하여 완료 시간을 예측합니다. 그것은 마지막에 매우 좋은 최종 완료 추정치를 제공 할 것이기 때문에 이전의 하룻밤 다운로드-최종 속도 향상 예제에서 꽤 잘 수행됩니다. 그러나 이것은 여전히 큰 문제를 안고 있습니다. 그것은 당신의 속도가 짧은 시간 동안 빠르게 변할 때 당신의 ETA가 격렬하게 튀어 오르게합니다. 그리고 당신은 "20 초 안에 완료, 2 시간 안에 완료, 2 초 안에 완료, 30 개 안에 완료됩니다. 분 "프로그래밍 수치의 빠른 표시.
실제 질문 :
계산 시간 기록을 고려할 때 작업 완료 예상 시간을 계산하는 가장 좋은 방법은 무엇입니까? GUI 툴킷이나 Qt 라이브러리에 대한 링크를 찾고 있지 않습니다. 가장 건전하고 정확한 완료 시간 추정치를 생성 하는 알고리즘 에 대해 묻고 있습니다.
수학 공식에 성공 했습니까? 어떤 종류의 평균화, 아마도 10 초 이상의 속도와 1 분 이상의 속도와 1 시간 이상의 속도의 평균을 사용하여? "내 새로운 추정치가 이전 추정치와 너무 많이 다를 경우 톤을 낮추고 너무 많이 바운스하지 마십시오"와 같은 일종의 인공 필터링? 완료시 통계적 오류 메트릭을 제공하기 위해 속도의 표준 편차를 찾기 위해 진행률 대 시간 향상을 통합하는 일종의 멋진 이력 분석?
무엇을 시도했으며 어떤 것이 가장 효과적입니까?
원래 답변
이 사이트를 만든 회사는 분명히 직원들이 코드를 작성하는 맥락에서이 질문에 답하는 일정 시스템을 만듭니다 . 작동 방식은 과거를 기반으로 한 미래의 몬테카를로 시뮬레이션입니다.
부록 : Monte Carlo에 대한 설명
다음은이 알고리즘이 귀하의 상황에서 작동하는 방식입니다.
작업을 일련의 마이크로 작업으로 모델링합니다 (예 : 1000 개). 한 시간 후에 100 개를 완료했다고 가정 해 보겠습니다. 이제 90 개의 완료된 마이크로 태스크를 무작위로 선택하고 시간을 더하고 10을 곱하여 나머지 900 개 단계에 대한 시뮬레이션을 실행합니다. 여기에 추정치가 있습니다. N 번 반복하면 남은 시간에 대해 N 개의 추정치가 있습니다. 이 추정치 사이의 평균은 약 9 시간이 될 것입니다. 그러나 결과 분포를 사용자에게 제시함으로써 그에게 확률을 솔직하게 전달할 수 있습니다. 예를 들어 '90 %의 확률로 이것은 3 ~ 15 시간이 더 걸릴 것입니다 '
정의에 따라이 알고리즘은 문제의 작업이 독립적 인 임의의 마이크로 작업으로 모델링 될 수있는 경우 완전한 결과를 생성합니다 . 작업이이 모델과 어떻게 다른지 알고있는 경우에만 더 나은 답을 얻을 수 있습니다. 예를 들어 설치 프로그램은 일반적으로 다운로드 / 압축 해제 / 설치 작업 목록을 가지고 있으며 한 쪽의 속도는 다른 쪽을 예측할 수 없습니다.
부록 : Monte Carlo 단순화
저는 통계 전문가는 아니지만이 방법에서 시뮬레이션을 자세히 살펴보면 항상 많은 수의 독립 랜덤 변수의 합으로 정규 분포를 반환 할 것이라고 생각합니다. 따라서 전혀 수행 할 필요가 없습니다. 실제로 완성 된 시간을 모두 저장할 필요도 없습니다. 그 합계와 제곱의 합만 필요하기 때문입니다.
표준 표기법이 아닐 수도 있습니다.
sigma = sqrt ( sum_of_times_squared-sum_of_times^2 )
scaling = 900/100 // that is (totalSteps - elapsedSteps) / elapsedSteps
lowerBound = sum_of_times*scaling - 3*sigma*sqrt(scaling)
upperBound = sum_of_times*scaling + 3*sigma*sqrt(scaling)
이것으로 이제부터는 [lowerBound, upperBound] 사이에서 어떤 고정 된 확률로 끝날 것이라는 메시지를 출력 할 수 있습니다 (약 95 %가되어야하는데 상수 인자를 놓친 것 같습니다).
내가 찾은 것이 잘 작동합니다! 작업의 처음 50 %에 대해서는 비율이 일정하고 외삽이라고 가정합니다. 시간 예측은 매우 안정적이며 많이 바운스되지 않습니다.
50 %를 통과하면 계산 전략 을 전환 합니다. 남은 작업의 일부 (1-p)를 취한 다음 자신의 진행 내역에서 시간을 거슬러 올라가서 (이진 검색 및 선형 보간으로) 마지막 작업을 수행하는 데 걸린 시간을 찾습니다 (1 -p) 백분율을 사용 하고 이를 시간 예상 완료로 사용 합니다 .
따라서 지금 71 %를 완료했다면 29 %가 남아 있습니다. 당신은 당신의 역사를 되돌아보고 얼마나 오래 전에 (71-29 = 42 %) 완료했는지를 알 수 있습니다. 그 시간을 ETA로보고하십시오.
이것은 자연스럽게 적응합니다. 할 일이 X 분이면 X 분의 일을하는 데 걸린 시간 만 봅니다. 마지막에 99 %를 완료하면 예상치에 매우 최신의 최신 데이터 만 사용됩니다.
물론 완벽하지는 않지만 매끄럽게 변경되며 특히 가장 유용 할 때 가장 정확합니다.
일반적으로 지수 이동 평균 을 사용하여 평활 계수가 0.1 인 작업의 속도를 계산하고이를 사용하여 남은 시간을 계산합니다. 이렇게하면 측정 된 모든 속도가 현재 속도에 영향을 미치지 만 최근 측정은 먼 과거의 측정보다 훨씬 더 많은 영향을 미칩니다.
코드에서는 다음과 같습니다.
alpha = 0.1 # smoothing factor
...
speed = (speed * (1 - alpha)) + (currentSpeed * alpha)
작업의 크기가 균일하다면 currentSpeed마지막 작업을 실행하는 데 걸린 시간입니다. 작업의 크기가 다르고 하나의 작업이 다른 작업보다 두 배 더 길어야한다는 것을 알고 있다면 작업을 실행하는 데 걸린 시간을 상대적 크기로 나누어 현재 속도를 얻을 수 있습니다. 를 사용 speed하면 나머지 작업의 총 크기 (또는 작업이 균일 한 경우 해당 수)를 곱하여 남은 시간을 계산할 수 있습니다.
내 설명이 충분히 명확하기를 바랍니다. 하루가 조금 늦었습니다.
모든 예제가 유효하지만 '다운로드까지 남은 시간'이라는 특정 사례의 경우 기존 오픈 소스 프로젝트에서 어떤 작업을 수행하는지 살펴 보는 것이 좋습니다.
내가 볼 수 있듯이 Mozilla Firefox는 남은 시간을 가장 잘 예측합니다.
모질라 파이어 폭스
Firefox는 남은 시간에 대한 마지막 추정치를 추적하고이 시간과 남은 시간에 대한 현재 추정치를 사용하여 시간에 대한 평활화 기능을 수행합니다. 여기 에서 ETA 코드를 참조 하십시오 . 이것은 이전에 여기 에서 계산 된 '속도'를 사용하며 마지막 10 개 판독 값의 평활화 된 평균입니다.
이것은 약간 복잡하므로 다른 말로 표현하면됩니다.
- 이전 속도의 90 %와 새 속도의 10 %를 기준으로 속도의 평활화 된 평균을 계산합니다.
- 이 평활화 된 평균 속도로 남은 예상 시간을 계산합니다.
- 이 남은 예상 시간과 이전 예상 남은 시간을 사용하여 새로운 예상 남은 시간을 생성합니다 (점프를 방지하기 위해).
구글 크롬
Chrome은 사방으로 뛰어 다니는 것처럼 보이며 코드 는 이것을 보여줍니다 .
Chrome에서 내가 좋아하는 한 가지는 남은 시간을 포맷하는 방법입니다. 1 시간 이상인 경우 '1 시간 남음'으로 표시됩니다. 1 시간 미만인 경우 '59 분 남음 '으로 표시됩니다. 1 분 미만인 경우 '52 초 남음'으로 표시됩니다.
여기 에서 형식이 어떻게 지정되었는지 확인할 수 있습니다.
DownThemAll! 매니저
영리한 것을 사용하지 않습니다. 즉, ETA가 여기 저기 뛰어 다니는 것을 의미합니다.
여기에서 코드 보기
pySmartDL (python 다운로더)
최근 30 개의 ETA 계산의 평균 ETA를 사용합니다. 그것을 수행하는 합리적인 방법처럼 들립니다.
여기 에서 코드를 참조 하십시오. /blob/916f2592db326241a2bf4d8f2e0719c58b71e385/pySmartDL/pySmartDL.py#L651)
전염
대부분의 경우 꽤 좋은 ETA를 제공합니다 (예상대로 시작할 때 제외).
Firefox와 비슷하지만 그렇게 복잡하지는 않은 지난 5 회 판독 값에 대해 평활 계수를 사용합니다. 근본적으로 Gooli의 답변과 유사합니다.
여기 에서 코드보기
특정 경우에 동일한 작업을 정기적으로 수행해야하는 경우 과거 완료 시간을 사용하여 평균을내는 것이 좋습니다.
예를 들어, COM 인터페이스를 통해 iTunes 라이브러리를로드하는 응용 프로그램이 있습니다. 주어진 iTunes 보관함의 크기는 일반적으로 항목 수 측면에서 시작될 때마다 크게 증가하지 않으므로이 예에서는 마지막 세 번의로드 시간과로드 속도를 추적 한 다음 그에 대해 평균을내는 것이 가능할 수 있습니다. 현재 ETA를 계산하십시오.
이것은 즉각적인 측정보다 훨씬 더 정확하고 아마도 더 일관적일 것입니다.
그러나이 방법은 이전 작업과 상대적으로 유사한 작업의 크기에 따라 달라 지므로 압축 해제 방법이나 주어진 바이트 스트림이 크런치 될 데이터 인 다른 작업에는 작동하지 않습니다.
내 $ 0.02
먼저, 이동 평균을 생성하는 데 도움이됩니다. 이는 최근 이벤트에 더 많은 가중치를 부여합니다.
이를 위해, 각각 한 쌍의 진행률과 시간이있는 여러 샘플 (원형 버퍼 또는 목록)을 유지합니다. 가장 최근 N 초의 샘플을 유지합니다. 그런 다음 샘플의 가중 평균을 생성합니다.
totalProgress += (curSample.progress - prevSample.progress) * scaleFactor
totalTime += (curSample.time - prevSample.time) * scaleFactor
scaleFactor는 과거 시간의 역함수로 0 ... 1에서 선형으로 이동합니다 (따라서 최근 샘플의 무게를 더 많이 측정). 물론이 가중치를 가지고 놀 수 있습니다.
마지막으로 평균 변화율을 얻을 수 있습니다.
averageProgressRate = (totalProgress / totalTime);
남은 진행 상황을이 숫자로 나누어 ETA를 계산하는 데 사용할 수 있습니다.
그러나 이것은 좋은 추세 수치를 제공하지만 지터라는 또 다른 문제가 있습니다. 자연적인 변화로 인해 진행률이 약간 이동하면 (시끄러운 경우)-예를 들어 파일 다운로드를 추정하는 데 이것을 사용하는 경우-소음으로 인해 ETA가 쉽게 이동할 수 있음을 알 수 있습니다. 꽤 먼 미래입니다 (몇 분 이상).
지터가 ETA에 너무 많은 영향을주지 않도록하려면이 평균 변경 률 수치가 업데이트에 느리게 응답하기를 원합니다. 이에 접근하는 한 가지 방법은 AverageProgressRate의 캐시 된 값을 유지하는 것입니다. 방금 계산 한 추세 수치로 즉시 업데이트하는 대신 질량이있는 무거운 물리적 개체로 시뮬레이션하고 시뮬레이션 된 '힘'을 천천히 적용합니다. 추세 번호쪽으로 이동합니다. 질량을 사용하면 약간의 관성이 있고 지터의 영향을 덜받습니다.
다음은 대략적인 샘플입니다.
// desiredAverageProgressRate is computed from the weighted average above
// m_averageProgressRate is a member variable also in progress units/sec
// lastTimeElapsed = the time delta in seconds (since last simulation)
// m_averageSpeed is a member variable in units/sec, used to hold the
// the velocity of m_averageProgressRate
const float frictionCoeff = 0.75f;
const float mass = 4.0f;
const float maxSpeedCoeff = 0.25f;
// lose 25% of our speed per sec, simulating friction
m_averageSeekSpeed *= pow(frictionCoeff, lastTimeElapsed);
float delta = desiredAvgProgressRate - m_averageProgressRate;
// update the velocity
float oldSpeed = m_averageSeekSpeed;
float accel = delta / mass;
m_averageSeekSpeed += accel * lastTimeElapsed; // v += at
// clamp the top speed to 25% of our current value
float sign = (m_averageSeekSpeed > 0.0f ? 1.0f : -1.0f);
float maxVal = m_averageProgressRate * maxSpeedCoeff;
if (fabs(m_averageSeekSpeed) > maxVal)
{
m_averageSeekSpeed = sign * maxVal;
}
// make sure they have the same sign
if ((m_averageSeekSpeed > 0.0f) == (delta > 0.0f))
{
float adjust = (oldSpeed + m_averageSeekSpeed) * 0.5f * lastTimeElapsed;
// don't overshoot.
if (fabs(adjust) > fabs(delta))
{
adjust = delta;
// apply damping
m_averageSeekSpeed *= 0.25f;
}
m_averageProgressRate += adjust;
}
Your question is a good one. If the problem can be broken up into discrete units having an accurate calculation often works best. Unfortunately this may not be the case even if you are installing 50 components each one might be 2% but one of them can be massive. One thing that I have had moderate success with is to clock the cpu and disk and give a decent estimate based on observational data. Knowing that certain check points are really point x allows you some opportunity to correct for environment factors (network, disk activity, CPU load). However this solution is not general in nature due to its reliance on observational data. Using ancillary data such as rpm file size helped me make my progress bars more accurate but they are never bullet proof.
Uniform averaging
The simplest approach would be to predict the remaining time linearly:
t_rem := t_spent ( n - prog ) / prog
where t_rem is the predicted ETA, t_spent is the time elapsed since the commencement of the operation, prog the number of microtasks completed out of their full quantity n. To explain—n may be the number of rows in a table to process or the number of files to copy.
This method having no parameters, one need not worry about the fine-tuning of the exponent of attenuation. The trade-off is poor adaptation to a changing progress rate because all samples have equal contribution to the estimate, whereas it is only meet that recent samples should be have more weight that old ones, which leads us to
Exponential smoothing of rate
in which the standard technique is to estimate progress rate by averaging previous point measurements:
rate := 1 / (n * dt); { rate equals normalized progress per unit time }
if prog = 1 then { if first microtask just completed }
rate_est := rate; { initialize the estimate }
else
begin
weight := Exp( - dt / DECAY_T );
rate_est := rate_est * weight + rate * (1.0 - weight);
t_rem := (1.0 - prog / n) / rate_est;
end;
where dt denotes the duration of the last completed microtask and is equal to the time passed since the previous progress update. Notice that weight is not a constant and must be adjusted according the length of time during which a certain rate was observed, because the longer we observed a certain speed the higher the exponential decay of the previous measurements. The constant DECAY_T denotes the length of time during which the weight of a sample decreases by a factor of e. SPWorley himself suggested a similar modification to gooli's proposal, although he applied it to the wrong term. An exponential average for equidistant measurements is:
Avg_e(n) = Avg_e(n-1) * alpha + m_n * (1 - alpha)
but what if the samples are not equidistant, as is the case with times in a typical progress bar? Take into account that alpha above is but an empirical quotient whose true value is:
alpha = Exp( - lambda * dt ),
where lambda is the parameter of the exponential window and dt the amount of change since the previous sample, which need not be time, but any linear and additive parameter. alpha is constant for equidistant measurements but varies with dt.
Mark that this method relies on a predefined time constant and is not scalable in time. In other words, if the exactly same process be uniformly slowed-down by a constant factor, this rate-based filter will become proportionally more sensitive to signal variations because at every step weight will be decreased. If we, however, desire a smoothing independent of the time scale, we should consider
Exponential smoothing of slowness
which is essentially the smoothing of rate turned upside down with the added simplification of a constant weight of because prog is growing by equidistant increments:
slowness := n * dt; { slowness is the amount of time per unity progress }
if prog = 1 then { if first microtask just completed }
slowness_est := slowness; { initialize the estimate }
else
begin
weight := Exp( - 1 / (n * DECAY_P ) );
slowness_est := slowness_est * weight + slowness * (1.0 - weight);
t_rem := (1.0 - prog / n) * slowness_est;
end;
The dimensionless constant DECAY_P denotes the normalized progress difference between two samples of which the weights are in the ratio of one to e. In other words, this constant determines the width of the smoothing window in progress domain, rather than in time domain. This technique is therefore independent of the time scale and has a constant spatial resolution.
Futher research: adaptive exponential smoothing
You are now equipped to try the various algorithms of adaptive exponential smoothing. Only remember to apply it to slowness rather than to rate.
I always wish these things would tell me a range. If it said, "This task will most likely be done in between 8 min and 30 minutes," then I have some idea of what kind of break to take. If it's bouncing all over the place, I'm tempted to watch it until it settles down, which is a big waste of time.
I have tried and simplified your "easy"/"wrong"/"OK" formula and it works best for me:
t / p - t
In Python:
>>> done=0.3; duration=10; "time left: %i" % (duration / done - duration)
'time left: 23'
That saves one op compared to (dur*(1-done)/done). And, in the edge case you describe, possibly ignoring the dialog for 30 minutes extra hardly matters after waiting all night.
Comparing this simple method to the one used by Transmission, I found it to be up to 72% more accurate.
나는 그것을 땀을 흘리지 않고 응용 프로그램의 매우 작은 부분입니다. 나는 그들에게 무슨 일이 일어나고 있는지 말하고 그들이 다른 일을하도록 내버려 둡니다.
참고 URL : https://stackoverflow.com/questions/933242/smart-progress-bar-eta-computation
'Nice programing' 카테고리의 다른 글
| MAX_PATH 문제가 Windows 10에 여전히 존재합니까? (0) | 2020.10.27 |
|---|---|
| vue.js의 구성 요소에 데이터 전달 (0) | 2020.10.27 |
| C / C ++에서 부호없는 왼쪽 시프트 이전의 마스킹이 너무 편집증 적입니까? (0) | 2020.10.27 |
| > 대> = 버블 정렬로 인해 상당한 성능 차이 발생 (0) | 2020.10.27 |
| .gitignore의 git 하위 모듈을 무시하거나 저장소에 커밋합니까? (0) | 2020.10.27 |